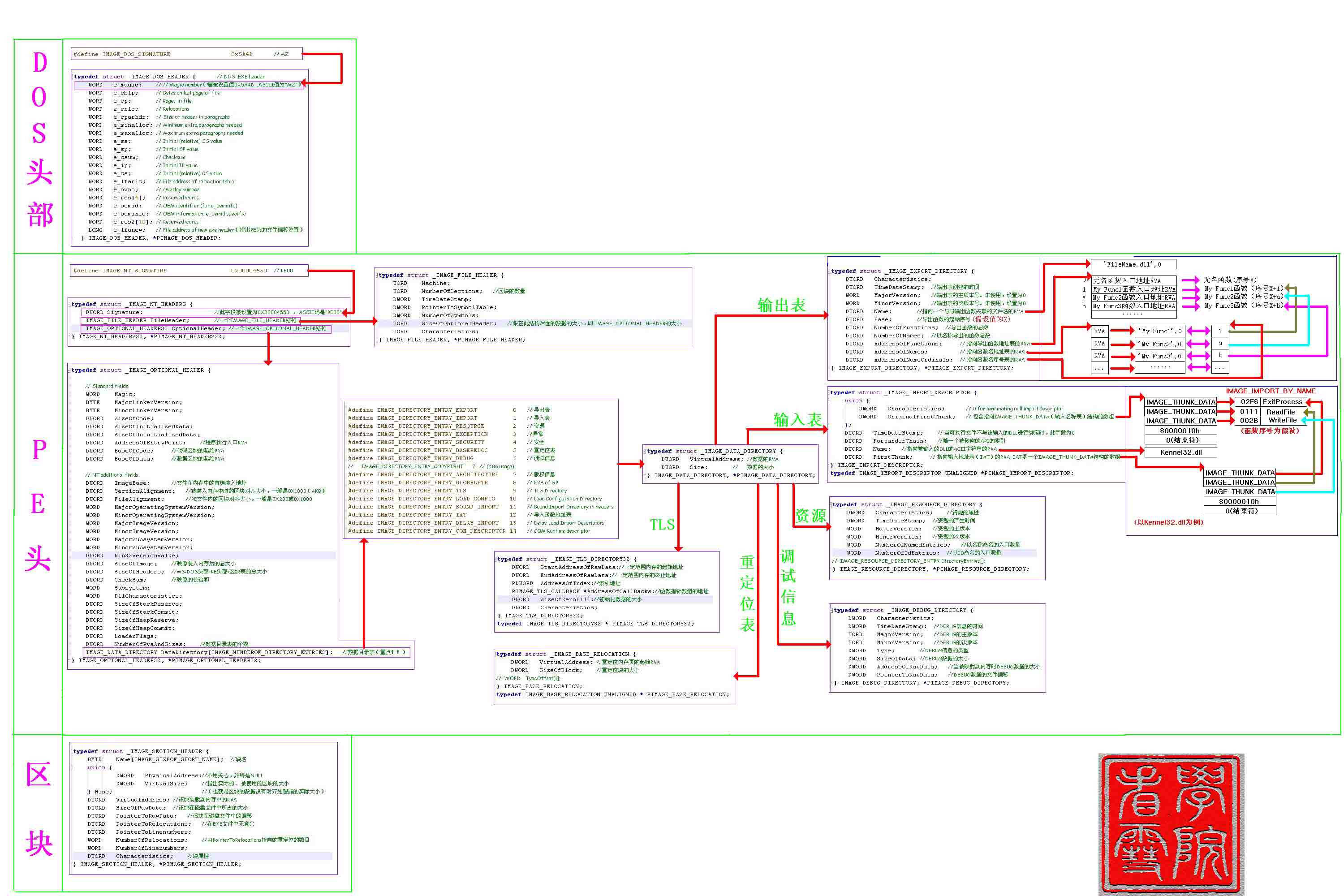
什么是PE文件? PE文件是Windows操作系统中常见的可执行文件格式,全称为Portable Executable。PE文件包含了程序的可执行代码、数据、资源和其他相关信息,是Windows系统上运行程序的标准格式。PE文件通常具有扩展名为”.exe”、”.dll”或”.sys”等,其中”.exe”文件是可执行文件,”.dll”文件是动态链接库文件,”.sys”文件是系统驱动文件。PE文件在Windows系统中被广泛使用,它包含了程序运行所需的信息,如程序入口点、导入表、导出表、资源表等,使得操作系统能够正确加载和执行程序。PE文件也是恶意软件分析和逆向工程中常见的文件格式。
PE文件结构图
上面的图片被压缩了,有点模糊。可以看原图
PE_Format_Poster.rar
或者看这里的图
bookmark
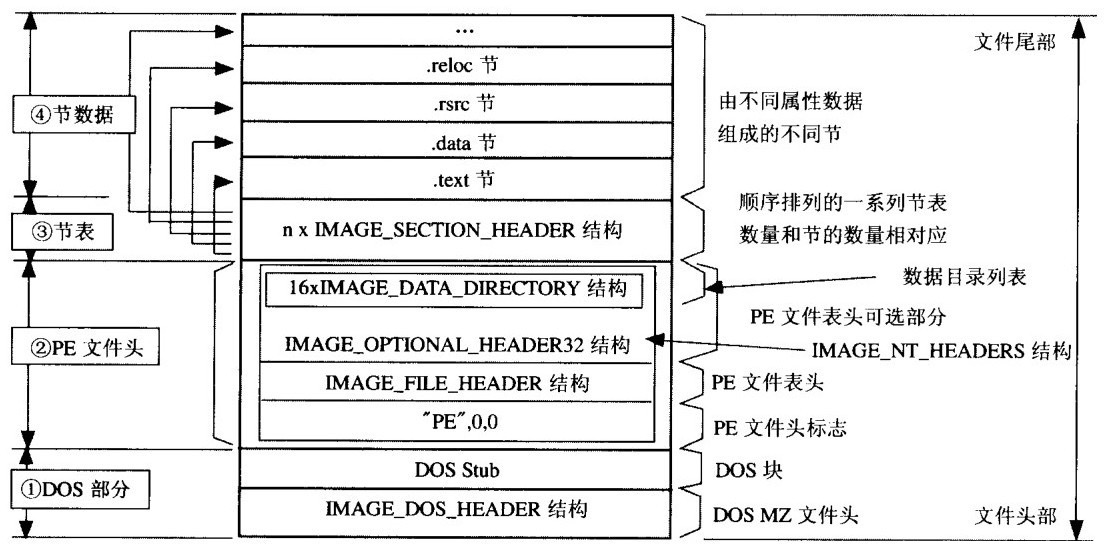
PE文件的整体结构 一个完整的PE文件主要有4个部分组成:
DOS头,PE头,节表以及节数据
1.Dos部分主要用来对非FE格式文件的处理,DOS时代遗留的产物,是PE文件的一个遗传基因;
2.PE头部分用于宏观上记录文件的一些信息,,运行平台,大小,创建日期,属性等。
3.节表部分用于对各中类型的数据进行定义分段;
4.节数据不言而喻就是文件的数据部分,实际上我们编写程序的过程中就是对该部分的数据进行编写。而其他的部分则是由编译器依照我们编写的部分进行相应的填写而得到的。
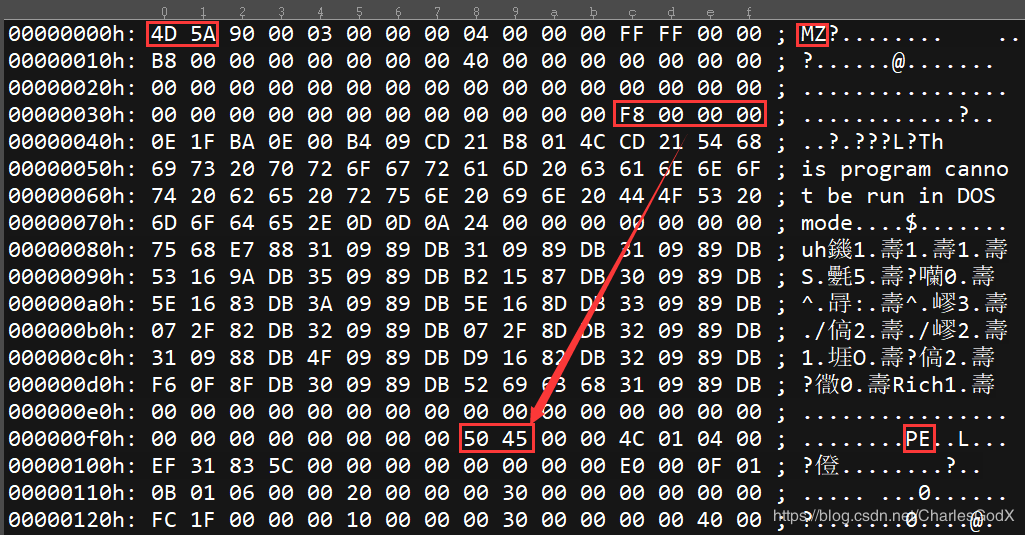
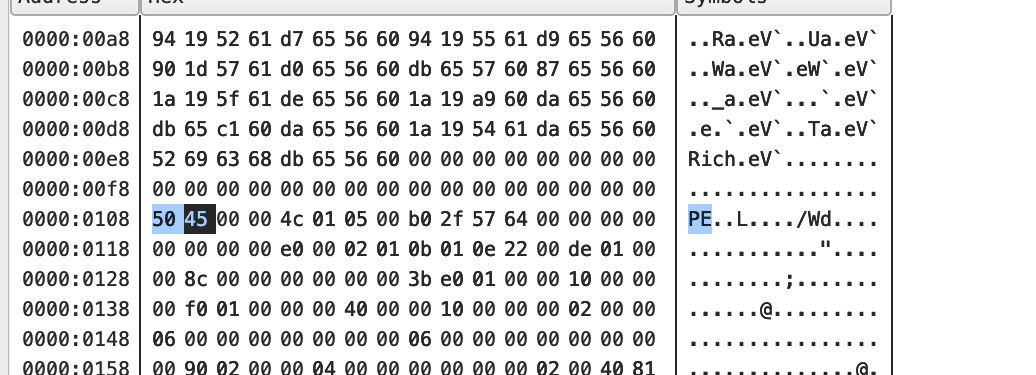
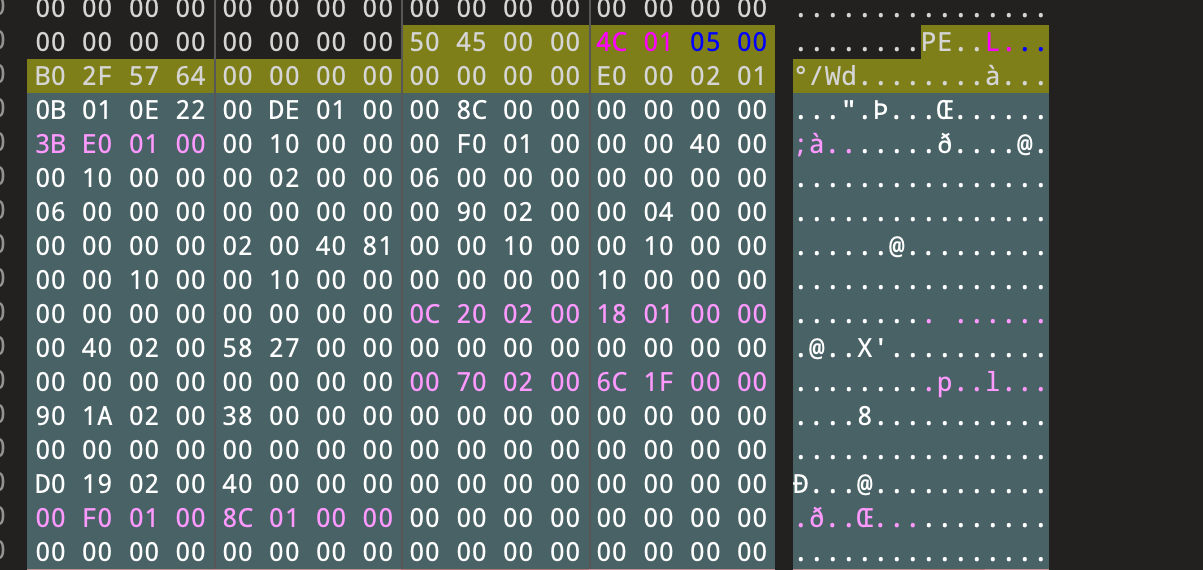
PE指纹 为了更加直观的描述我们用16进制编辑器直接将一个exe文件载入,分析其结构,首先我们需要清楚的概念是PE指纹,也就是判断一个文件是否是PE文件的依据,首先是根据文件的前两个字节是否为4D 5A,也就是’MZ’,然后看第四排四个字节指向的地址00 00 00 f8是否为50 45,也就是’PE’,满足这两个条件也就满足了PE文件的格式,简称PE指纹,在后面制作解析器的时候会通过它来判断是否为一个有效的PE文件。
我这里使用了这个跨平台的PE文件查看器来解析PE文件
link_preview
💡 010Editor这个二进制编辑器也支持PE文件的查看了,很方便
当然你也可以使用StudyPE这个老牌的工具
bookmark
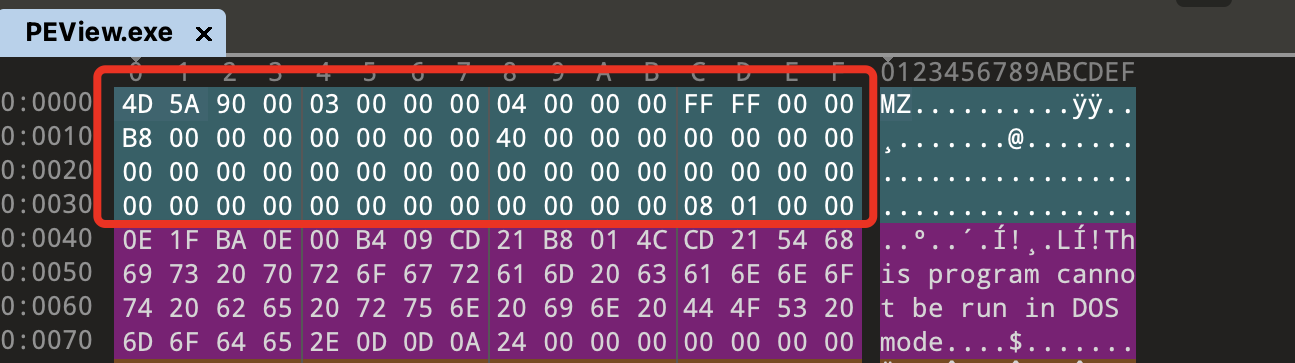
DOS部分 DOS部分主要是为了兼容以前的DOS系统,DOS部分可以分为DOS MZ文件头(IMAGE_DOS_HEADER)和DOS块(DOS Stub)组成,PE文件的第一个字节位于一个传统的MS-DOS头部,称作IMAGE_DOS_HEADER,其结构如下:
typedef struct _IMAGE_DOS_HEADER { // DOS .EXE header WORD e_magic; // Magic number WORD e_cblp; // Bytes on last page of file WORD e_cp; // Pages in file WORD e_crlc; // Relocations WORD e_cparhdr; // Size of header in paragraphs WORD e_minalloc; // Minimum extra paragraphs needed WORD e_maxalloc; // Maximum extra paragraphs needed WORD e_ss; // Initial (relative) SS value WORD e_sp; // Initial SP value WORD e_csum; // Checksum WORD e_ip; // Initial IP value WORD e_cs; // Initial (relative) CS value WORD e_lfarlc; // File address of relocation table WORD e_ovno; // Overlay number WORD e_res[4]; // Reserved words WORD e_oemid; // OEM identifier (for e_oeminfo) WORD e_oeminfo; // OEM information; e_oemid specific WORD e_res2[10]; // Reserved words LONG e_lfanew; // File address of new exe header } IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
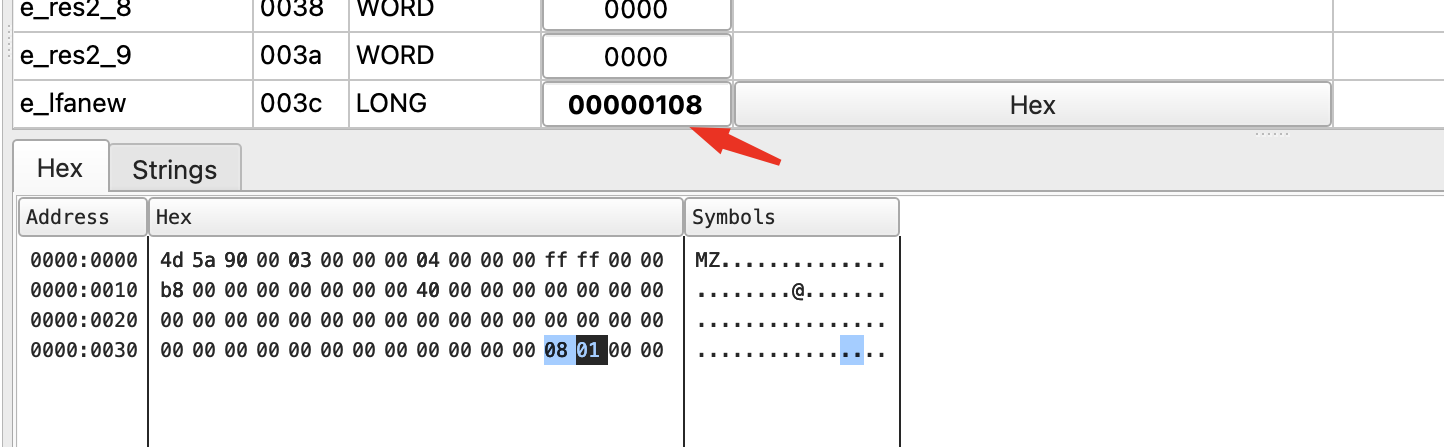
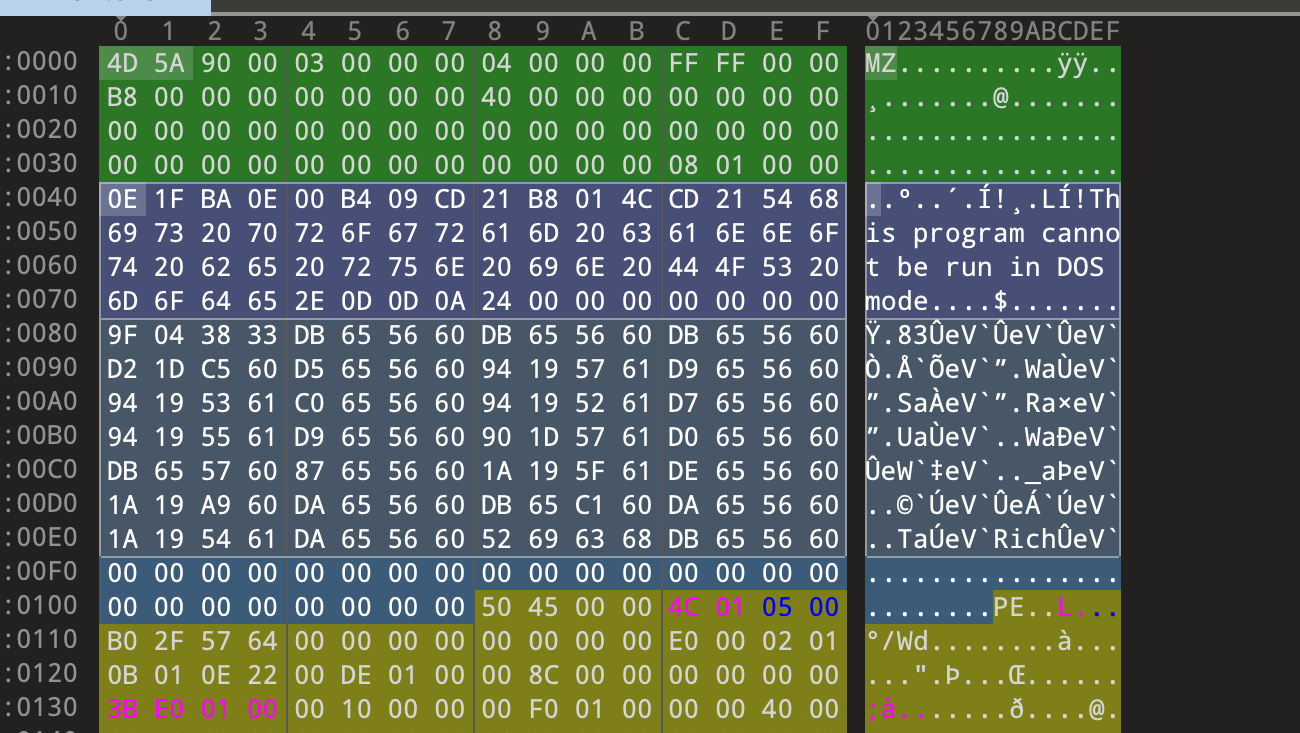
DOS部分我们需要熟悉的是e_magic成员和e_lfanew成员,前者是标识PE指纹的一部分,后者则是寻找PE文件头的部分,除了这两个成员,其他成员全部用0填充都不会影响程序正常运行,所以我们不需要过多的对其他部分深究,DOS部分在16进制编辑器中看就是下图的部分:
DOS头总共40个字节。
我们可以看到e_lfanew指向PE文件头,我们可以通过它来寻找PE文件头,而DOS块的部分自然就是PE文件头和DOS MZ文件头中间的部分,这部分是由链接器所写入的,可以随意进行修改,并不影响程序的运行:
e_lfanew的值为1080 ,说明PE文件头开始的位置为1080
图中蓝色部分无意义,可随意修改,不影响程序运行。
PE文件头 PE header 由三部分组成
字串“PE\0\0”(Signature):以此识别给定文件是否为有效PE文件。映像文件头(FileHeader):结构域包含了关于PE文件物理分布的信息。可选映像头(OptionalHeader)
PE文件头由PE文件头标志,标准PE头,扩展PE头三部分组成。PE文件头标志自然是50 40 00 00,也就是’PE’,我们从结构体的角度看一下PE文件头的详细信息
typedef struct _IMAGE_NT_HEADERS { DWORD Signature; //PE文件头标志 => 4字节 IMAGE_FILE_HEADER FileHeader; //标准PE头 => 20字节 IMAGE_OPTIONAL_HEADER32 OptionalHeader; //扩展PE头 => 32位下224字节(0xE0) 64位下240字节(0xF0) } IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
标准PE头结构如下,有20个字节,我们可以从PE文件头标志后20个字节找到它
typedef struct _IMAGE_FILE_HEADER { WORD Machine; //可以运行在什么平台上 任意:0 ,Intel 386以及后续:14C x64:8664 WORD NumberOfSections; //节的数量 DWORD TimeDateStamp; //编译器填写的时间戳 DWORD PointerToSymbolTable; //调试相关 DWORD NumberOfSymbols; //调试相关 WORD SizeOfOptionalHeader; //标识扩展PE头大小 WORD Characteristics; //文件属性 => 16进制转换为2进制根据哪些位有1,可以查看相关属性 } IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
扩展PE头在32位和64位系统上大小是不同的,在32位系统上有224个字节,16进制就是0xE0,结构如下,重要的属性我都有标注
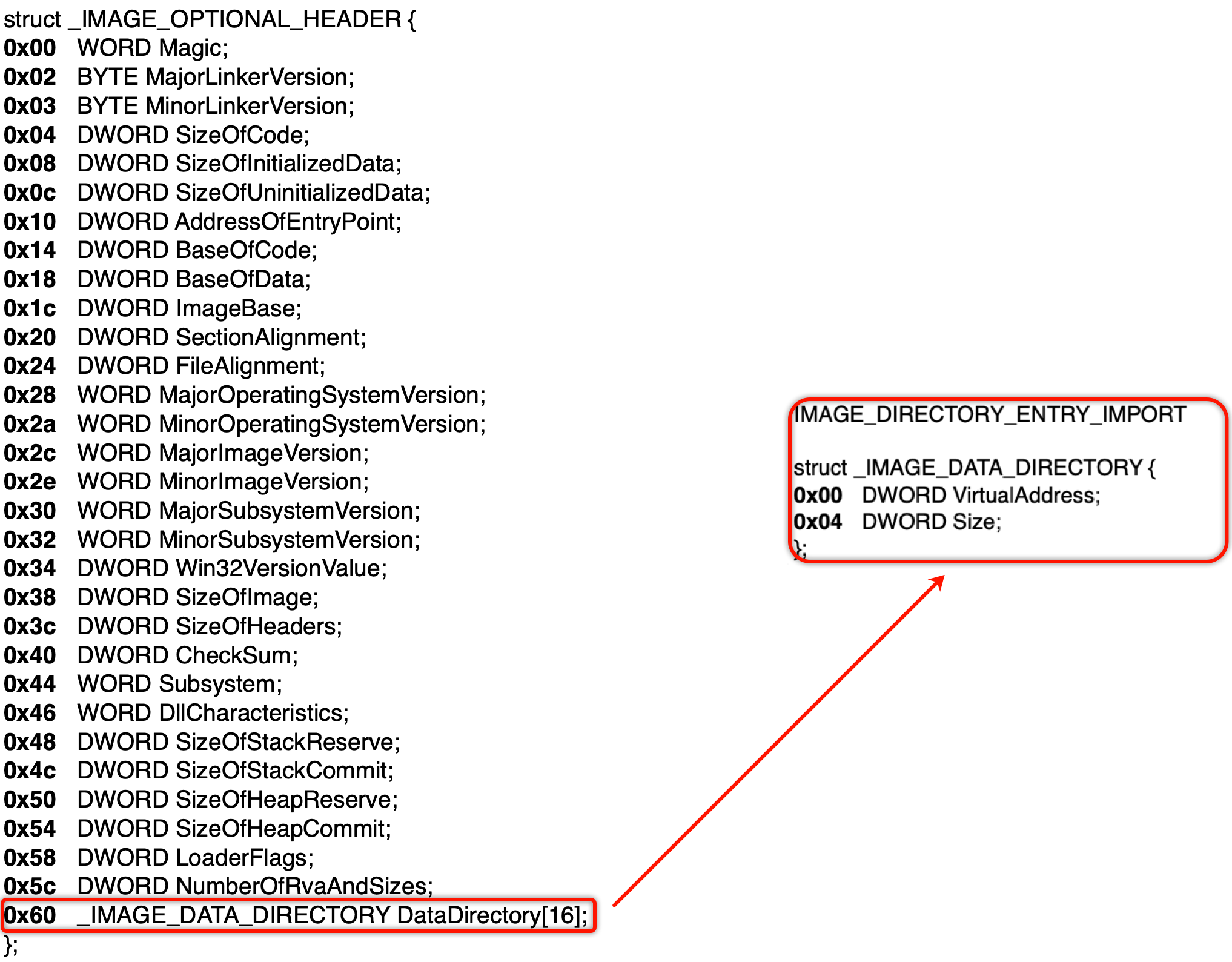
IMAGE_OPTINAL_HEADER在几乎所有的参考书中都被称作“可选头”。虽然被称作可选头,但是该头部不是一个可选的,而是一个必须存在的头,不可以没有。该头被称作“可选头”的原因是在该头的数据目录数组中,有的数据目录项是可有可无的,数据目录项部分是可选的,因此称为“可选头”。它定义了PE文件的很多关键信息。大小可从 文件头-IMAGE_FILE_HEADER 中得知。
typedef struct _IMAGE_OPTIONAL_HEADER { // // Standard fields. // WORD Magic; //PE32: 10B PE64: 20B BYTE MajorLinkerVersion; BYTE MinorLinkerVersion; DWORD SizeOfCode; //所有含有代码的区块的大小 编译器填入 没用(可改) DWORD SizeOfInitializedData; //所有初始化数据区块的大小 编译器填入 没用(可改) DWORD SizeOfUninitializedData; //所有含未初始化数据区块的大小 编译器填入 没用(可改) DWORD AddressOfEntryPoint; //程序入口RVA DWORD BaseOfCode; //代码区块起始RVA DWORD BaseOfData; //数据区块起始RVA // // NT additional fields. // DWORD ImageBase; //内存镜像基址(程序默认载入基地址) DWORD SectionAlignment; //内存中对齐大小 DWORD FileAlignment; //文件中对齐大小(提高程序运行效率) WORD MajorOperatingSystemVersion; WORD MinorOperatingSystemVersion; WORD MajorImageVersion; WORD MinorImageVersion; WORD MajorSubsystemVersion; WORD MinorSubsystemVersion; DWORD Win32VersionValue; DWORD SizeOfImage; //内存中整个PE文件的映射的尺寸,可比实际值大,必须是SectionAlignment的整数倍 DWORD SizeOfHeaders; //所有的头加上节表文件对齐之后的值 DWORD CheckSum; //映像校验和,一些系统.dll文件有要求,判断是否被修改 WORD Subsystem; WORD DllCharacteristics; //文件特性,不是针对DLL文件的,16进制转换2进制可以根据属性对应的表格得到相应的属性 DWORD SizeOfStackReserve; DWORD SizeOfStackCommit; DWORD SizeOfHeapReserve; DWORD SizeOfHeapCommit; DWORD LoaderFlags; DWORD NumberOfRvaAndSizes; IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES]; //数据目录表,结构体数组 } IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
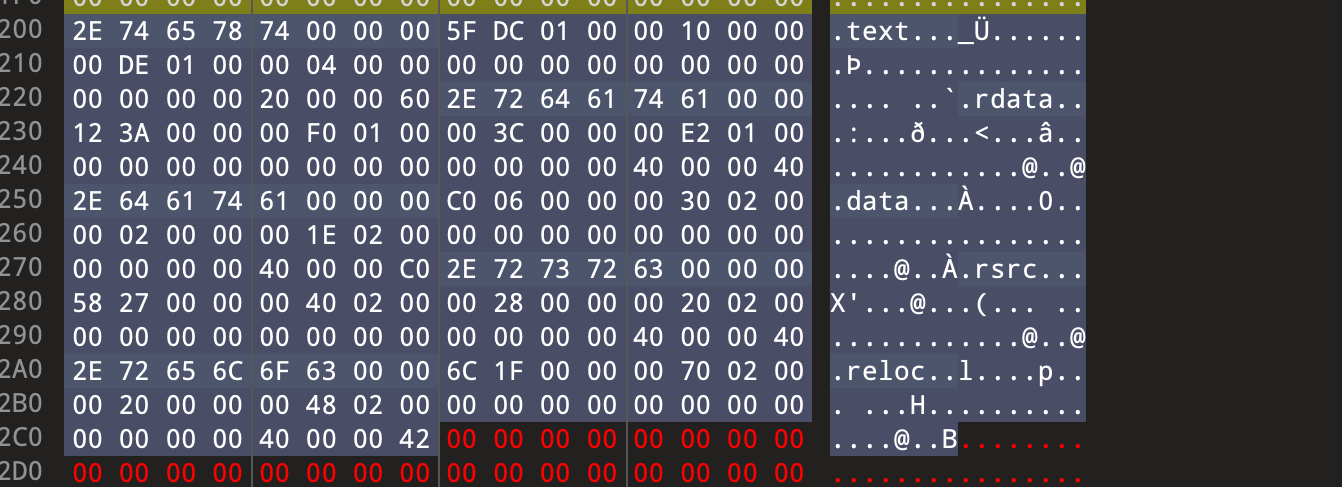
图中标颜色的就是整个PE文件头
扩展PE头中标注了程序的入口点:
程序的真正入口点 = ImageBase + AddressOfEntryPoint
这里先注意下,这部门还需要细说,我们先看后面的部分。
PE节表 这里建议看下这篇文章中写的关于块表和块的地方:
bookmark
在PE中,节数据有几个,分别对应着什么类型以及其他相关的属性都是由PE节表来决定的,PE节表是一个结构体数组,结构体的定义如下所示,整体大小为40个字节:
#define IMAGE_SIZEOF_SHORT_NAME 8 typedef struct _IMAGE_SECTION_HEADER { BYTE Name[IMAGE_SIZEOF_SHORT_NAME]; // ASCII字符串(节名),可自定义,只截取8个字节,可以8个字节都是名字 union { // Misc,双字,是该节在没有对齐前的真实尺寸,该值可以不准确 DWORD PhysicalAddress; // 真实宽度,这两个值是一个联合结构,可以使用其中的任何一个 DWORD VirtualSize; // 一般是取后一个 } Misc; DWORD VirtualAddress; // 在内存中的偏移地址,加上ImageBase才是在内存中的真正地址 DWORD SizeOfRawData; // 节在文件中对齐后的尺寸 DWORD PointerToRawData; // 节区在文件中的偏移 DWORD PointerToRelocations; // 调试相关 DWORD PointerToLinenumbers; // 调试相关 WORD NumberOfRelocations; // 调试相关 WORD NumberOfLinenumbers; // 调试相关 DWORD Characteristics; // 节的属性 } IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
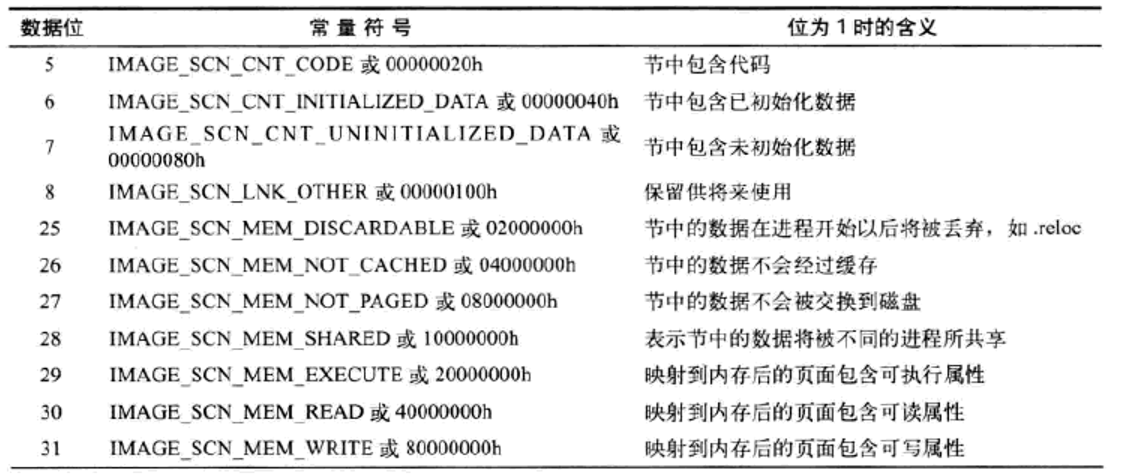
与其他结构体一样,PE节也有属性,这就是成员Characteristics,其数据宽度是16位(4字节),其每一数据位对应的属性如下所示:
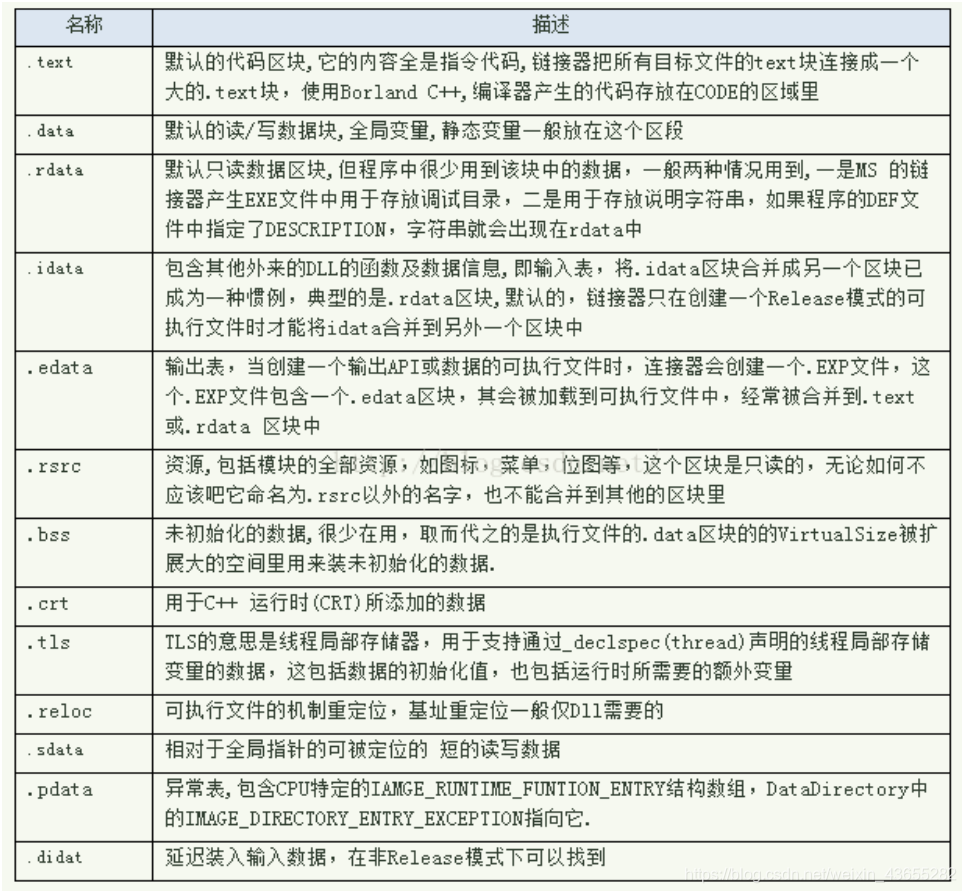
区块(节) 每个区块的名称都是唯一的,不能有同名的两个区块。
💡 可是 IMAGE_OPTIONAL_HEADER32 中并没有各区块的地址啊,咋定位?
区块名称及其意义
导出表 一个可执行程序是由多个PE文件组成,这些PE文件依靠倒入表、导出表进行联系,导出表存储着PE文件提供给其他人使用的函数列表,导入表则存储着PE文件所需要用到的PE文件列表。从PE文件的角度去看,任何PE文件都可以有导入、导出表,从一般情况下来看,EXE文件不会提供导出表,也就是不会提供给他人使用的函数,但这并不代表不可以提供,导出表(Export Table)一般是DLL文件用的比较多,exe文件很少有导出表。
定位导出表
在PE格式图中,扩展PE头最后一个成员是结构体数组,在这个结构体数组里面有16个结构体,第一个结构体就是导出表相关的信息,它有2个成员,一个表示导出表的地址,一个表示导出表的大小。如下图所示中的**_IMAGE_EXPORT_DIRECTORY**,就是PE导出表的结构:
typedef struct _IMAGE_EXPORT_DIRECTORY { DWORD Characteristics; DWORD TimeDateStamp; WORD MajorVersion; WORD MinorVersion; DWORD Name; // 指针指向该导出表文件名字符串 DWORD Base; // 导出函数起始序号 DWORD NumberOfFunctions; // 所有导出函数的个数 DWORD NumberOfNames; // 以函数名字导出的函数个数 DWORD AddressOfFunctions; // 指针指向导出函数地址表RVA DWORD AddressOfNames; // 指针指向导出函数名称表RVA DWORD AddressOfNameOrdinals; // 指针指向导出函数序号表RVA } IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
可以看到导出表里面最后还有三个表,这三个表可以让我们找到函数真正的地址,在编写PE格式解析器的时候可以用到,AddressOfFunctions 是函数地址表,指向每个函数真正的地址,AddressOfNames 和 AddressOfNameOrdinals 分别是函数名称表和函数序号表,我们知道DLL文件有两种调用方式,一种是用名字,一种是用序号,通过这两个表可以用来寻找函数在 AddressOfFunctions 表中真正的地址。
关于导出表的利用可以看下这篇文章中的导出表部分:
bookmark
导入表 PE文件所依赖的模块以及涉及到依赖模块中的具体函数都存储在导入表中,我们可以在PE格式图的扩展PE头最后一个成员结构体数组中的第二个结构体找到导出表相关的信息,它有2个成员,一个表示导入表的地址,一个表示导入表的大小:
导入表与导出表不同,导出表只有一张,而导入表有很多张,每一张表对应着不同的依赖模块,导入表的结构如下,它一共有20字节:
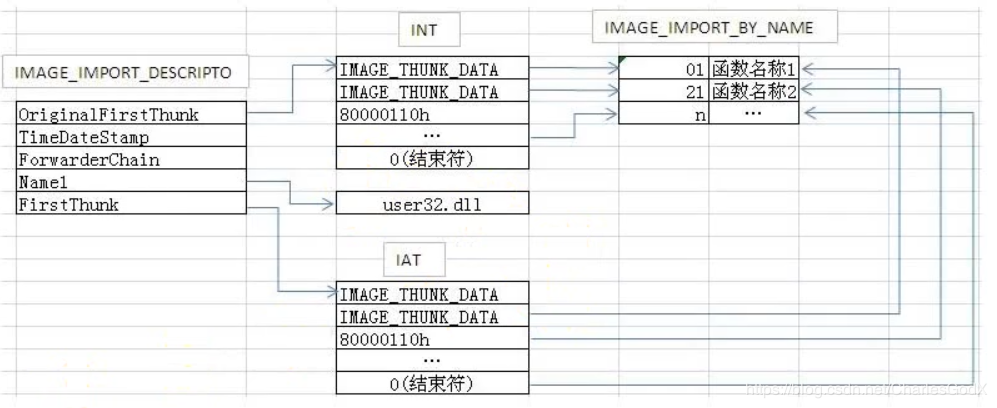
typedef struct _IMAGE_IMPORT_DESCRIPTOR { union { DWORD Characteristics; // 0 for terminating null import descriptor DWORD OriginalFirstThunk; // RVA 指向 INT (PIMAGE_THUNK_DATA结构数组) } DUMMYUNIONNAME; DWORD TimeDateStamp; // 0 if not bound, // -1 if bound, and real date\time stamp // in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND) // O.W. date/time stamp of DLL bound to (Old BIND) DWORD ForwarderChain; // -1 if no forwarders DWORD Name; //RVA指向dll名字,以0结尾 DWORD FirstThunk; // RVA 指向 IAT (PIMAGE_THUNK_DATA结构数组) } IMAGE_IMPORT_DESCRIPTOR; typedef IMAGE_IMPORT_DESCRIPTOR UNALIGNED *PIMAGE_IMPORT_DESCRIPTOR;
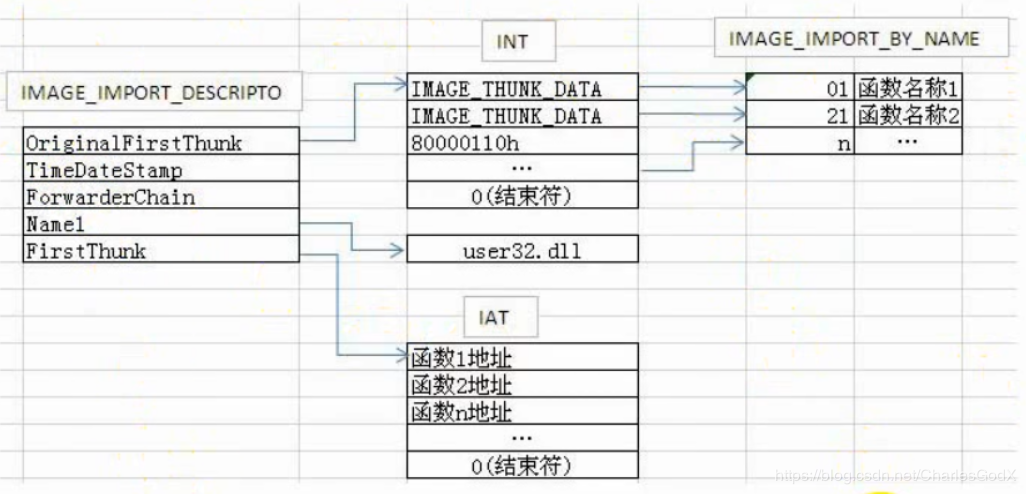
可以看到,OriginalFirstThunk 和 FirstThunk 指向的内容分别是 INT 和 IAT ,但实际上 INT 和 IAT 的内容是一样的,所以他们指向的内容是一样的,只是方式不同而已,下图可以完美的解释
但是上图只是PE文件加载前的情况,PE文件一旦运行起来,就会变成下图的情况
我们还需要了解的结构体是 IMAGE_THUNK_DATA 和 IMAGE_IMPORT_BY_NAME 结构如下
typedef struct _IMAGE_IMPORT_BY_NAME { WORD Hint; //可能为空,编译器决定,如果不为空,是函数在导出表的索引 BYTE Name[1]; //函数名称,以0结尾 } IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME; #include "pshpack8.h" // Use align 8 for the 64-bit IAT. typedef struct _IMAGE_THUNK_DATA64 { union { ULONGLONG ForwarderString; // 指向一个转向者字符串的RVA ULONGLONG Function; // 被输入的函数的内存地址 ULONGLONG Ordinal; // 被输入API的序数值 ULONGLONG AddressOfData; // 指针指向 IMAGE_IMPORT_BY_NAME } u1; } IMAGE_THUNK_DATA64; typedef IMAGE_THUNK_DATA64 * PIMAGE_THUNK_DATA64; #include "poppack.h" // Back to 4 byte packing typedef struct _IMAGE_THUNK_DATA32 { union { DWORD ForwarderString; // PBYTE DWORD Function; // PDWORD DWORD Ordinal; DWORD AddressOfData; // PIMAGE_IMPORT_BY_NAME } u1; } IMAGE_THUNK_DATA32; typedef IMAGE_THUNK_DATA32 * PIMAGE_THUNK_DATA32;
其实他们的作用很明显,就是用来寻找当前的模块依赖哪些函数,可以用这几个结构体求到依赖函数的名字。
关于怎么手动的去找导入表中依赖的dll和函数名,可以看下这篇文章中的导入表部分.
bookmark
重定位表 在PE中最重要的三张表就是导出、导入和重定位表,本章来了解一下重定位表。
重定位表是什么?假设某一PE文件使用了一些模块,这些模块都有自己的ImageBase(在内存中开始的地址),但是实际上在内存中模块的ImageBase被别人占用了,这时候模块就需要偏移,换一个新的内存地址去展开 ,假设在这模块中有很多已经写好了地址的硬编码(但凡涉及到直接寻址的指令都需要进行重定位处理 ),当换了地址之后就找不到了,甚至会出现安全隐患,所以硬编码的地址是需要随着偏移而去修改的,这时候就需要一张表去记录需要修正的位置,便于去根据对应偏移修正,这张表我们就称之为重定位表 ;一般来说,EXE文件是没有重定位表的 ,因为它不会提供函数给其他人用(导出表),所以运行时它理应是第一个载入内存中的,而DLL之类的PE文件则一定是需要重定位表的,因为它并不一定会加载在ImageBase上。
重定位表的位置信息与导入、导出表一样,在扩展PE头的最后一个成员中的第6个结构体,结构体的成员与导入、导出表一样,分别表示重定位表的起始位置和大小:
重定位表中有一个结构体,它一共有8字节:
typedef struct _IMAGE_BASE_RELOCATION { DWORD VirtualAddress; // RVA DWORD SizeOfBlock; } IMAGE_BASE_RELOCATION; typedef IMAGE_BASE_RELOCATION ,* PIMAGE_BASE_RELOCATION;
重定位表有许多个,以八个字节的 0 结尾
但是完整的重定位表还包含了很多重定位项,所以整体大小是没有一个统一标准的,需要根据实际情况。该结构体的第一个成员VirtualAddress表示基地址,第二个成员SizeOfBlock也就是减去当前结构体的大小之后其他的所有重定位项加起来的大小 。
这也就表示每一个重定位表是IMAGE_BASE_RELOCATION结构体开始,跟着的就是重定位项。
从理论上来说,重定位表中存储的项应该都是4字节大小的地址,但是这样一旦需要修改的地址多了,就会占用大量的空间,所以重定位表就做了一些优化,假设你现在有这几个地址需要修正:
那么优化之后,IMAGE_BASE_RELOCATION结构体的第一个成员存储的就是0x800000,而这个结构体之后的每2字节存储就包含 0x123、0x456、0x789,这样就大大的节省了空间。同时,这也就说明重定位表的实际大小为IMAGE_BASE_RELOCATION结构体(8字节)+N*2字节。
重定位表是按照一个物理页(4KB)进行存储的,也就表示一个4KB内存有需要修正的位置,就会有一个重定位块,一个重定位表只管自己当前的物理页的重定位。
但需要注意的是由于内存对齐的缘故,在重定位表中还是有很多的无用项的,所以你需要判断当前重定位项(2字节)的高四位是否为3,如果是那么低12位就是偏移量,最后的地址也就是 VirtualAddress+低12位 ,如果不是就表示这是无所谓的值 。
PE结构解析C语言代码 bookmark
参考 bookmark
bookmark
bookmark